20 Aug 2017
러스트 개발 툴을 찾아서
러스트를 공부하면서 ‘언제쯤 괜찮은 IDE가 함께 나올까’에 대한 바램이 많이 있었더랬습니다.
러스트 1.0이 발표된 지 2년쯤이 지났고,
그동안 언어 내부에 많은 개선이 이루어져 현재 러스트 컴파일러의 버전은 1.19까지 올라갔지만,
왠지 IDE에 대한 공식적인 지원을 나서는 곳이 없었지요. 러스트에 관심을 갖고 공부하는 사람들은
왠지 다 vi 계열 혹은 emacs 계열의 에디터로 불편함없이 프로그래밍하는 고수들인가부다 하고 생각하고는
했습니다.
러스트 개발 환경을 구축해보려고 제가 써본 것들은
- Sublime text
- Visual Studio Community edition + Visual Rust
- JetBrains CLion + Intelli Rust
- Visual Studio Code (이하 VSCode) + Rust extension
정도가 있고, 현재는 VSCode를 계속 이용하고 있습니다.
Sublime text에서 제공하는 강력한 기능은 좋지만 텍스트 에디터로서의 기본적인 한계가 있었고,
Visual Studio는 좋았지만 윈도우 환경 외에서 잘 사용할 수 있을지 모르겠고
(최근 MacOSX용이 나왔지만
아직 안써봐서 어떤지 잘 모르겠습니다), CLion은 크로스 플랫폼이고 기능도 강력하긴 한데 살짝 느린 감이
있었지요 (이쪽도 본격적으로 러스트를 위한 IDEA 계열 에디터용 공식 플러그인을 만든다고 발표했습니다. 이것도 좀더 기다려봐야 할 것 같아요).
VSCode는 순전히 러스트 때문에 설치해본 것인데, Sublime text의 강력한 에디팅 기능을 포함하면서 매우 긴
길이의 텍스트에 대해서도 빠른 처리를 하는걸 보고 - 대략 15만줄 짜리도 금방 로딩되더군요 - 일반 텍스트
에디팅에서도 최근 가장 애용하는 에디터가 되었습니다. 심지어 공짜입니다; 저는 서브라임 정품도 구매해서 쓰고
있었는데!
VSCode + RLS
VSCode에서 사용할 수 있는 러스트용 extension 중에는 Rusty code라는 녀석과
Rust라는 녀석 두 가지가 있었는데, 이 둘은 racer와 rustfmt, rustsrc를 사용하여 코드 컴플리션과
리포맷팅 기능을 제공하고, 각종 cargo 관련 기능을 추가해 줍니다. 종종 사용하다가 보면 좌측 하단의
status bar에 racer가 crash되었다고 나오면, 재빨리 VSCode를 reload 해주면서 썼습니다 (…)
그러던 중, 최근 RLS 개발진중 한 분이 블로그에 홍보글을 썼더군요.
RLS는 Rust Language Server라고 하는 것으로, 백그라운드로 실행되면서 IDE나 에디터, 혹은 다른
툴에게 개발하고 있는 러스트 프로그램에 대한 정보를 제공하는 서버입니다. 글을 훑어보시면 여러가지
매력적인 기능이 있습니다. 마우스를 심볼 위에 호버링 시키면 해당 심볼의 선언부분이 나온다던지,
go to definition이라던지요.
이전에도 이 RLS는 계속 개발되고 있었고, VSCode extension 중에서 Rust를 이용하면
실험적인 feature로 RLS를 이용해볼지, 아니면 legacy 방식을 쓸지 결정하라고 물어봤었지요.
이때 한번 RLS를 써보려다가… 너무 버그가 심해서 (RLS 서버가 너무 픽픽 죽어서) 쓰질 못했었어요.
근데 블로그로 홍보를 하는 상황이 되었고, 심지어 이를 위해 직접 extension도 만들었다니까,
한번 써봐야되지 않겠습니까? 그래서 써봤습니다.
결론은, RLS analysis는 좀 오래 걸리긴 하지만, 매우 만족스럽다는 것이었습니다!
이제부터 어떤식으로 VSCode + RLS를 이용하여 개발 환경을 구축했는지에 대한 내용을
공유할까 합니다.
개발 환경 구축
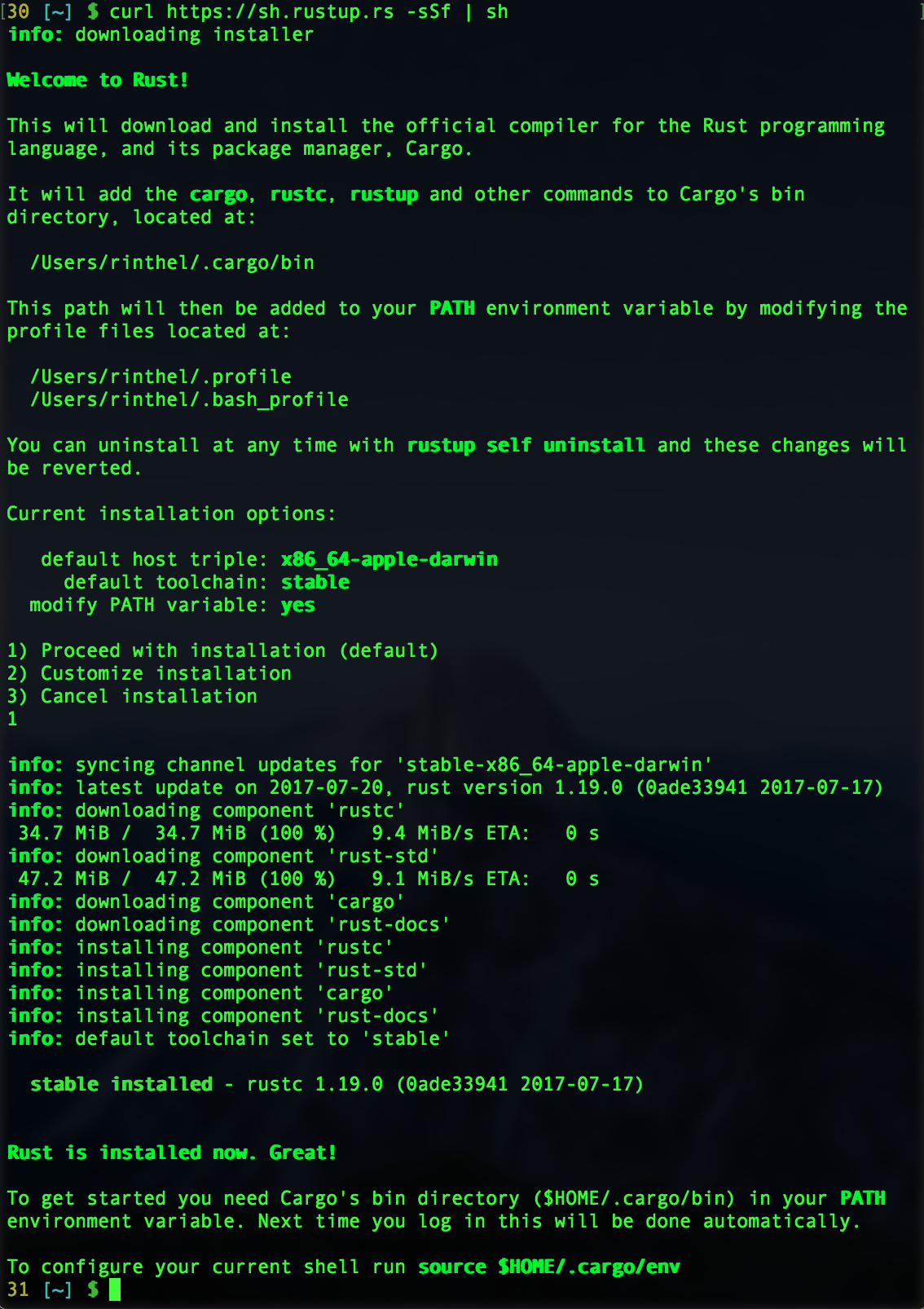
Rustup 설치
- 상당히 많은 언어들이 그렇듯, 러스트도 버전 매니저가 있습니다. rustup이라고 부르는데요.
홈페이지에 가면 설치 방법이 한줄 나와 있습니다.
curl https://sh.rustup.rs -sSf | sh
- 혹시 윈도우 유저시라면, 홈페이지 하단에 other installation options라고 되어있는
링크를 타고 들어가셔서 설치 옵션을 보세요.
- rustup 없이도 러스트를 설치할 수 있지만, rustup을 이용하면 개발에 필요한 다양한
콤포넌트들을 쉽게 설치할 수 있으니, 이 방법을 이용하는 것을 강력히 추천합니다.
- rustup으로 설치를 마치셨다면, 기본적으로 현재 이용할 수 있는 stable 버전의 rustc
컴파일러 및 cargo 패키지 매니저, 그리고 러스트 문서와 표준 라이브러리가 설치되는걸
확인할 수 있습니다 (작성일 기준 1.19버전입니다).
- 덧: 만일 윈도우 유저라면, rustup을 이용하여 설치할 수 있는 환경이 두 가지입니다:
visual studio 기반 혹은 mingw 기반이죠. 원하시는데로 설치하시면 됩니다.
제 경험상으로는 visual studio community edition을 설치하고 visual studio
기반으로 설치하는 쪽이 디버깅 환경 등을 이용할때 좀 더 좋았습니다.
VSCode 설치
VSCode 내에 extension 설치
- VSCode에서 go to file (
ctrl + p)를 열어서 ext install rust이라고
입력하면, 검색어에 걸리는 몇 개의 extension이 좌측 사이드 탭에 뜹니다.
- 이중에서
Rust (rls)라고 되어있는 extension을 설치하고 reload 하세요.
- 팁: command pallete (
ctrl + shift + p)를 눌러서 reload를 검색하면
매우 빠르게 에디터 리로딩을 할 수 있어요.
러스트 프로젝트 만들고 열기
- 러스트 프로젝트를 열지 않고는 Rust (rls)의 세부 환경 세팅이 안될테니, hello world
프로젝트라도 하나 만들어봅시다.
- 터미널을 열고 다음을 입력하여 프로젝트를 만들고 VSCode로 엽니다:
$ cargo new hello_world --bin
$ code ./hello_world
rustup component 설치
- 프로젝트를 성공적으로 여셨다면, VSCode에 설치된 Rust(RLS) extension이 자동적으로 현재 상태를 감지하고,
필요한 rustup component를 설치하려고 할 것입니다.
- 먼저 설치하라고 하는 것은 nightly toolchain 입니다. 현재 RLS가 nightly 버젼에서만 돌아가기 때문이지요.
yes를 눌러서 설치를 진행합니다.

- 설치가 끝나고 나면, 다음으로 RLS를 설치하려고 할 것입니다. 역시 yes를 눌러서 설치를 진행합니다.

- 설치가 다 끝나고 나면, 기본적인 에디팅 환경 설정은 모두 끝난 것입니다. 좌측 하단에
RLS analysis: done이라고 뜨면 동작을 하고 있다는 얘기입니다.

- 간략한 예제를 작성하면서 테스트 해보세요. 심볼에 마우스를 갖다대면 해당 심볼의 선언 부분이 나오고,
ctrl + LMB을 누르면 해당 심볼의 정의 부분으로 이동합니다 (go to definition).
- 만약에 생각만큼 auto completion이나 go to definition 등이 잘 동작하지 않는다는 생각이 든다면,
VSCode를 reload 시켜보세요 (…) 종종 이게 제일 좋은 해결책일 경우가 있습니다. 다행스러운 것은 VSCode
reload가 정말 빠르게 실행된다는 것이죠 (…)
- 덧: 현재 설치된 rustup component를 보시려면 터미널에서
rustup component list를 실행하여 볼 수 있습니다.
다만, 디폴트로 설정되어 있는 toolchain에 대한 component만 보일 것이므로, rustup default nightly를 먼저
실행하셔야 제대로 된 리스트를 보실 수 있을 겁니다.
디버깅 환경 구축
Rust(rls) extension에서는 아직 공식적으로 디버거 연결 제공을 해주고 있지 않습니다. 대신,
gdb와 (windows 환경이라면 visual studio debugger) native debugger extension을
이용하면 대충 비스무리한 환경을 만들 수 있습니다.
gdb 설치
- 맥 유저시라면, gdb 대신 lldb가 기본 디버거라서 gdb가 따로 설치되어 있지 않을 수 있습니다.
brew를 이용해서 gdb를 설치해두시기 바랍니다.
- 현재의 macosx 버전에서는 gdb에 코드사인이 되어 있어야 정상적으로 동작합니다.
여기를 참고하셔서 gdb에
코드사인 작업을 하셔야 합니다.
- 또한 맥 유저라면 brew로 gdb을 설치한 뒤에 아래 메세지가 안내됩니다. 그대로 따라하셔서
gdb 기본 설정을 해줘야 합니다:
$ echo "set startup-with-shell off" >> ~/.gdbinit
VSCode native debug extension 설치
- 이 gdb를 VSCode에 연결해 주려면 Native Debug extension이 필요합니다.
ctrl + p를 눌러서 명령창을 열고 ext install native-debug를 입력하시면
좌측 사이드 탭에 Native Debug를 검색하실 수 있습니다. 이걸 인스톨합니다.
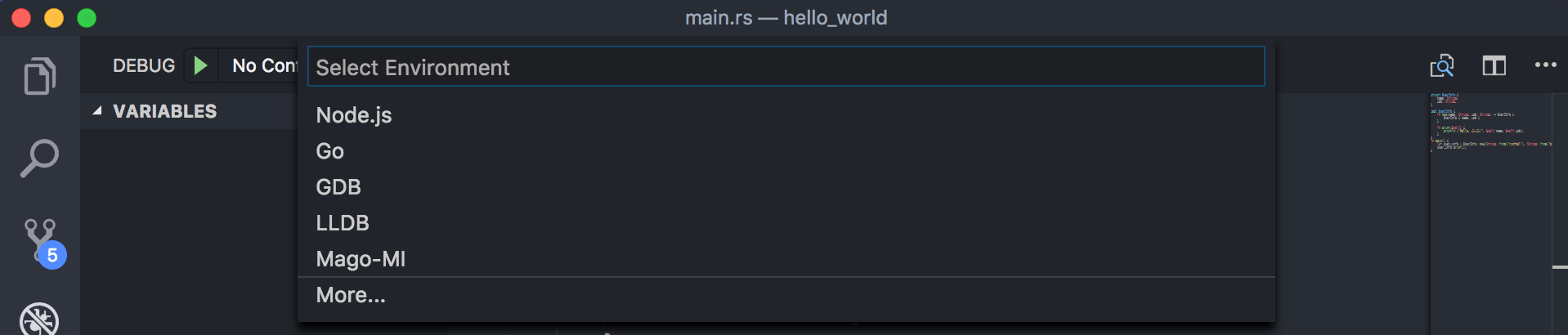
- reload를 하고 나서 이제 왼쪽 사이드 툴바에서 디버그 탭을 선택한 다음, 왼쪽 사이드 탭 상단에 있는
디버그 시작 아이콘을 누르면 새로운 디버깅 환경 세팅을 위한 메뉴가 뜹니다. 여기서 gdb를 선택해줍니다.
- 디버깅 환경을 선택하면 프로젝트 루트 디렉토리 밑에 있는
.vscode라는 디렉토리 안에 launch.json이라는
파일이 생기고, 여기에 자세한 디버깅 환경을 세팅할 수 있습니다. 우리가 해줘야 할 일은 target에 디버깅용
실행 파일 이름을 적어주는 것입니다.
- 여기서 주의해야할 사항은, 현재 맥에서는 gdb을 이용한 디버깅이 왠지 최종 파일인
./target/debug/{project_name}을 설정해주면 심볼 데이터를 잘 읽어들이지 못한다는 점입니다.
그럴때는 ./target/debug/dep/{project_name}_{뭔가 긴 해쉬코드} 파일을 찾아서 이 이름을 적어주세요.
혹시 같은 이름의 파일이 여러 개라면, cargo clean 후 cargo build를 다시 실행시키면 현재 이용하고 있는
하나만 나올 것입니다:
{
"name": "Debug",
"type": "gdb",
"request": "launch",
"target": "./target/debug/deps/hello_world-51d02c6c0c01c7ba",
"cwd": "${workspaceRoot}"
}
- 이제 코드에 브레이크 포인트를 설정하고 디버그 모드를 실행시키면, 어느정도 동작하는 모습을 확인할 수 있습니다.
로컬 스코프의 변수를 자동으로 찾아서 채워주거나 하지는 않지만, 커서를 심볼에 갖다대면 현재 어떤 값을 갖고 있는지
확인할 수 있고, gdb에 익숙하신 분들이라면 debug console을 그대로 이용할 수도 있습니다:
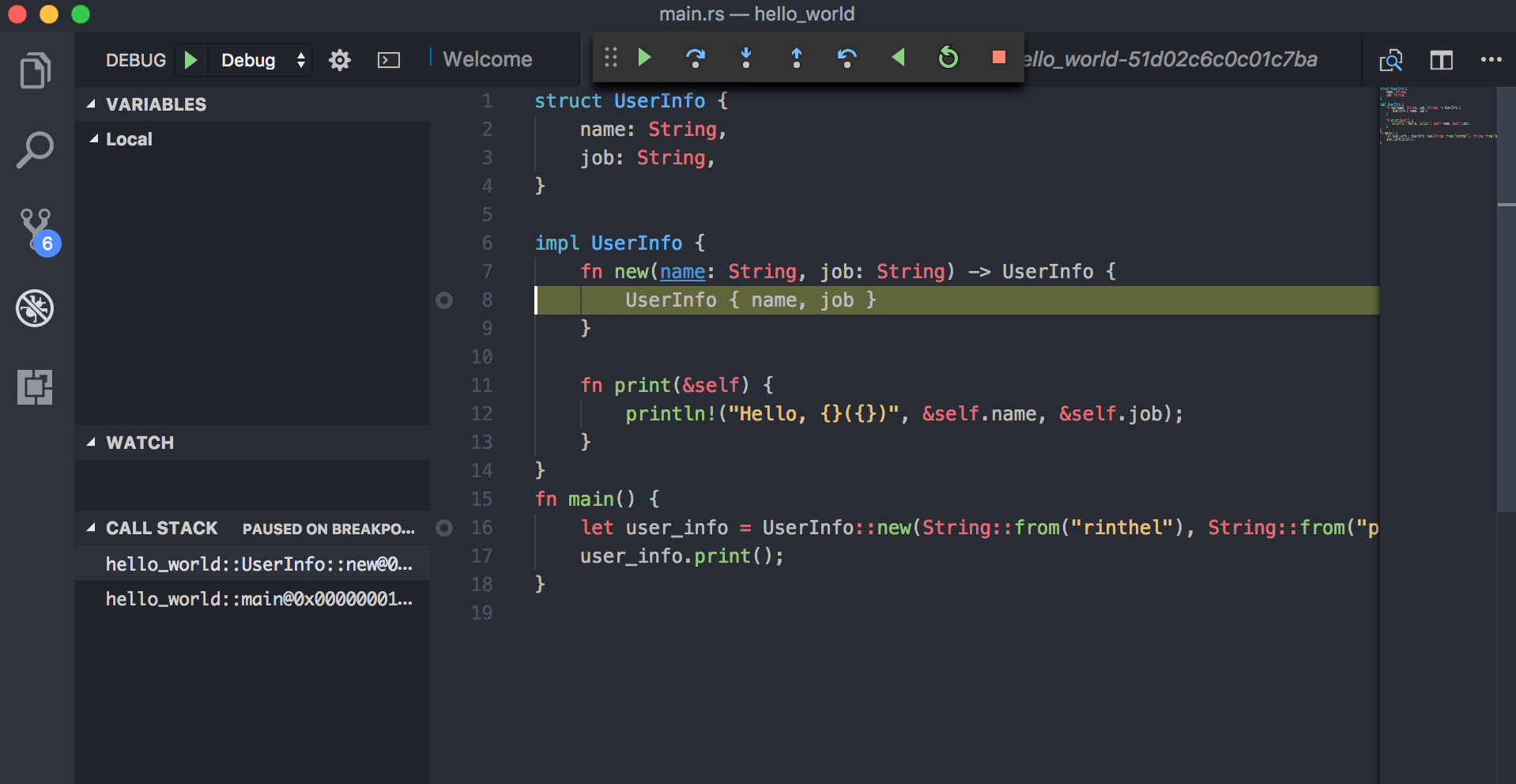
- 덧: 그냥 gdb를 이용하여 심볼 안의 데이터를 보면 타입 이름이 전부 적혀있어서 엄청 지저분합니다;
다행히 이걸 조금이라도 더 깔끔하게 보여줄 방법이 있습니다.
~/.gdbinit을 열어서 아래처럼 작성하고
저장하시면, gdb 상에서 좀더 깔끔하게 정리된 (그러나 여전히 json 비스무리해서 보기 그렇게 깔끔하진
않은) 데이터를 볼 수 있습니다! 아래에 ${여러분의_홈디렉토리} 부분과
nightly-x86_64-apple-darwin 부분 등 디렉토리 설정과 관련된 부분은 여러분의 상황에
맞게 고치셔야 합니다!
set startup-with-shell off
python
print "--Loading Rust pretty-printers--"
sys.path.insert(0, "${여러분의_홈디렉토리}/.rustup/toolchains/nightly-x86_64-apple-darwin/lib/rustlib/etc")
import gdb_rust_pretty_printing
gdb_rust_pretty_printing.register_printers(gdb)
end
정리
종종 VSCode + Rust(RLS)가 말을 안듣고 좀 불안하긴 하지만, 제가 이제까지 본 중 가장 쾌적한 러스트 개발 환경이
아닐까 싶습니다. VSCode랑 Rust(RLS)가 말을 안들으면 재빨리 reload하면 되고(…) 타이핑 할 때 느려지는 문제는
거의 없으며, Sublime text와 같은 강력한 멀티 커서 기능, 어느 정도 수준 이상으로 동작하는 코드 리팩터링 기능,
리포매팅 기능 등 필요한 건 어느정도 다 갖춘 상태입니다. 거기에 예쁘게 나오진 않지만 gdb를 이용해서 디버거 연결도
됩니다!
추후에 공식으로 나올 IntelliJ Rust도 기대하는 중입니다 후후후
Comment count
25 Jun 2017
바빠서 한동안 Rust 소식지를 못보고 있다가, 오늘 밤에 자기 전에 좀 읽어볼까 하고 C++에서 Rust로 갈아탄
어느 프로그래머의 얘기를 읽어보고 있던 중, 존경해 마지 않는 Braid와 The Witness의 개발자 Jonathan
Blow님께서 새로운 프로그래밍 언어인 Jai를 개발하는 중이라는 소식을 접하였습니다. 2014년 9월경 부터
개발이 진행되었고 아직 정식 출시를 한 상태는 아니라, Jonathan Blow님이 직접 올리고 있는 유튜브 영상으로
이 언어의 특성에 대해 확인만 할 수 있는 수준이긴 하지만; 그래도 너무 궁금하여 이것저것 찾아보던 중 영상의
내용을 토대로 Jai에 관한 내용을 정리한 BSVino라는 분의 Github 페이지가 있어 이를 간략히 번역해볼까
합니다. 저도 번역하면서 자세히 읽을라구요. (제가 Blow 게임의 덕후라서 그렇기도 합니다.)
출처: BSVino/JaiPrimier
JaiPrimer
소개
Jai는 인디 게임 Braid와 The Witness를 개발한 Jonathan Blow가 개발한 고수준 프로그래밍 언어입니다. 이 언어는 C 스타일의 정적/강타입 언어입니다만, C에 부족한 다양한 현대적 언어 특성을 갖고 있습니다. Blow는 2014년 9월 하순부터 Jai 개발을 시작했습니다. 지금도 여전히 개발중에 있고 그래서 아직 공개는 되지 않은 상태입니다. Blow는 이 언어를 비디오 게임을 위한 관점으로 개발하고 있지만, 실은 어떤 작업에도 사용 가능한 범용 언어입니다.
Disclaimer: 저는 Blow와 아무 관계가 없습니다. Jai를 위한 공식 컴파일러가 없는 이 시점에서, 이 문서의 모든 정보는 그런 이유로 Blow의 유튜브 비디오로 부터 가져온 것입니다. 따라서 이 문서는 공식적인 것이 아닙니다. 이 문서에 나온 내용보다 더 업데이트된 정보가 있을지도 모릅니다. 그러니까 저는 이 문서의 모든 내용이 업데이트 되어야 할거라 믿습니다. (만일 당신이 Jon Blow 본인이고 이 포스트 내용 어딘가를 고치라고 하고 싶다면, 환영합니다!)
이 문서의 모든 내용은 현재 Blow의 개인적인 프로토타입 내에서 개발되고 구현된 것이지만, 아직 출시되지 않았으므로, 어떤 것도 바뀔 가능성이 있습니다.
간략한 설명
짧게 말해서, Jai는 C의 현대적인 대체자라고 표현할 수 있겠습니다. 몇가지 멋진 기능을 나열해보자면,
- 임의 컴파일 타임 코드 실행 - 프로그램 내 어떤 함수라도
#run을 이용해서 컴파일 타임에 실행되게 할 수 있습니다.
- 문법적으로 수월한(Syntax-facilitated) 코드 리팩토링 - 코드를 코드 블록, 지역 함수, 전역 함수로 이동하기 쉽게 하는 방식을 통해서, 언어의 문법 자체가 코드의 재사용을 수월하게 합니다.
- 통합된(Integrated) 빌드 과정 - 견고한 설정을 위해, 빌드 과정과 파라미터가 소스 코드 자체에 설정되어 있습니다.
- 데이터 지향 구조체(Data-oriented structures) - 배열의 구조체(structure of arrays)와 구조체의 배열(array of structures) 간의 자동 전환 기능, 클래스와 상속 구조 안쓰기.
- 리플렉션(reflection) 및 런타임 타입 정보 - 모든 구조체에 대한 정적 타입 정보가 런타임에 접근 가능합니다.
- 다형적 프로시져(polymorphic procedures)에 대한 새로운 접근 - 프로그래머가 특수한 프로시져를 제어함으로써 함수 레벨에서의 다형성을 지원합니다.
- 저수준 메모리 관리 도구 - 라이브러리들이 메모리에 할당되는 방법에 대해 더 나은 방식의 제어가 가능하고, 자동 소유관 관리(automatic ownership management) 기능을 제공합니다. 가비지 콜렉션은 없습니다.
- 최적화와 퍼포먼스 특성에 대한 명시적인 제어 - 인라인, 바운스 체킹, 초기화와 같은 부분에 대한 명시적인 제어를 할 수 있습니다.
Jai의 철학
즐거운 프로그래밍
프로그래밍을 시작한지 몇년 지난 어느 시점에서, ‘신나는 프로그래밍 모험’과 ‘으어 제발 또 리팩토링 안했으면’ 사이의 선이 흐릿해지기 시작할 수 있습니다. 여러분이 함수의 시그니처를 변경할 때 헤더 파일의 함수 선언 부분을 수정해야 하는 짓은 낡았습니다. C가 처음 개발되던 시점인 1973년에는 헤더같은 것들이 필요한 좋은 이유가 있었지만, 지금은 아니죠. 언어에 의한 삶의 질 향상은 언어를 이용하는 프로그래머의 생선성으로 측정 가능한 이점을 가질 수 있습니다. (만일 여러분이 이를 납득하지 못한다면, Brainfuck을 이용해서 아무거나 프로그래밍 해보세요.) 컴파일은 즉각적이지는 않더라도 무척 빨라야 하고, 코드의 리팩토링은 최소의 변경만으로도 가능해야 하고, 에러 메세지는 유쾌하고 도움이 될 수 있어야 합니다. Blow는 프로그래머가 사용하는 도구의 개선이 20% 이상의 생산성 증가를 만들 수 있다고 믿었고, 이것이 곧 새로운 언어를 만드는 첫번째 동기가 되었습니다.
메모리 채우는 기계
비디오 게임이란, Blow의 말에 따르면, 메모리를 채우는 기계입니다. 게임 프로그래머들은 대부분의 시간을 어떻게 하면 어마어마한 양의 데이터를 메모리 안에 넣어서 이를 효율적으로 접근하고 처리할수 있도록 할지에 대해 생각합니다. 메모리의 수백 메가바이트가 하드 디스크에서 메인 메모리로 이동해야 하고, 또 데이터 처리를 위해 거기서 비디오 카드나 프로세서 캐시로 이동한 뒤 다시 메모리로 돌아와야 합니다. 비디오 게임 플레이어들은 기다리는 것을 싫어하기 때문에, 이런 모든 것들은 우리 세상의 법 안에서 허용 가능한 수준 내에서 최대한 빨리 이루어져야 합니다. 프로그래밍 언어의 가장 중요한 목적은 데이터를 관리하도록 알고리즘을 특정하는 것입니다. 가비지 콜렉션과 템플릿화된 데이터 스트림, 그리고 동적 스트링 클래스와 같은 언어 특성은 프로그래머가 코드 구현을 빠르게 하는데 도움을 줄지도 모르겠지만, 프로그래머가 빠르게 동작하는 코드를 작성하도록 돕진 않습니다.
마찰 제거
Jai의 또다른 디자인 목표는 Blow가 프로그래밍에서 마찰이라 부르는 것을 제거하는 것입니다. 마찰은 언어의 문법이 프로그래머의 작업과정을 훼방놓을 때 생깁니다. 자바는 모든 객체를 클래스가 되도록 요구하고, 그래서 프로그래머가 필요한 전역 변수를 전역 클래스에 집어넣도록 강요하게 될 때, 이런 것이 마찰입니다. 하스켈이 모든 프로시져를 함수가 되도록 요구하고 어떤 side effects도 없을 때, 이런 것이 마찰입니다. C++의 람다 함수 문법이 클래스 내 메소드 문법과 다르고, 또 전역 함수 문법과도 다를 때, 이런 것이 마찰입니다. 자바, 하스켈, 그리고 C++을 Blow가 “큰 어젠다” 언어라고 부르는 예들인데, 이는 언어에 대한 이상주의가 (C++의 경우는 확고한 비전의 부재가) 프로그래머의 방식대로 들어있는 것들입니다. Blow는 그의 언어에서 마찰을 최소한도로 유지하고자 합니다. 특히 마찰이 불필요하다면 더더욱.
좋은 프로그래머를 위한 디자인
Blow는 나쁜 프로그래머들이 아나라 좋은 프로그래머들을 위한 언어를 원합니다. 자바 같은 언어는 쉽게 다를 수 있다고 홍보되었고, 이는 프로그래머가 그들을 다치게 만들 수 있는 코드를 작성하기 훨씬 어려워집니다. Jai의 철학은, 만일 여러분이 여러분의 프로젝트에 나쁜 코드를 작성하는 바보가 되기 싫다면, 바보를 고용하지 말라는 겁니다. Jai는 프로그래머로 하여금 작업이 수행될 수 있도록 하는 날카로운 도구들을 바로 접근할 수 있도록 해줍니다. 프로그래머들은 실수도 하고 이는 때때로 크래쉬, 어쩌면 더 심각한 짓을 하기도 하지만, Blow는 메모리 안정적인 메카니즘이 있을 때가 에러 추적에 필요한 시간을 소비하는 때보다 생산성의 향상과 마찰의 제거에 더 안 좋다고 주장합니다. 특히 좋은 프로그래머들이 상대적으로 거의 에러를 만들지 않는 경향이 있을때 더욱 그렇다고 하지요.
성능과 데이터 지향 프로그래밍
만일 프로그래머로서 여러분이 사용자 경험을 고려한다면 (당연히 그래야겠지만), 여러분은 여러분의 프로그램의 성능을 좋게 해야 할 것입니다. 여러분은 코드가 작동하는 기계의 범위 내에서 여러분의 코드의 행동에 대해 추론하고, 데이터를 디자인하여 하드웨어가 가진 능력을 최대한 효과적으로 이용하기 위한 구조체를 제어해야 합니다. (저는 Mike Acton의 데이터 지향 디자인 방법론에 대해 서술한 것입니다.) 목표 하드웨어에 대한 소프트웨어의 성능에 대해 걱정하는 프로그래머는 하드웨어와 그들 사이에 앉아있는 프로그래밍 언어에 의해 억눌려집니다. 버추얼 머신이나 자동 메모리 관리 같은 메카니즘은 목표 하드웨어에서의 프로그램의 성능을 추론하고자 하는 프로그래머의 능력을 저해시킵니다. RAII, 생성자나 소멸자, 다형성, 예외처리와 같은 추상화는 게임 프로그래머들이 갖고 있지 않은 문제를 풀기 위한 의도로 고안되었으며, 그래서 게임 프로그래머가 가지고 있는 문제를 풀기 위한 해결책을 만드는 것을 방해하기도 합니다. Jai는 이런 추상화를 내던졌고, 그래서 프로그래머는 그들의 실제 문제, 즉 데이터와 그들의 알고리즘에 더 생각할 수 있습니다.
Jai 언어 특성
타입과 선언
name: type = value; 문법은 name이라는 이름의 변수가 type 타입이며 value값을 받음을 정의합니다. 이는 Sean Barrett에 의해 제안되었습니다. 몇가지 예제를 보자면,
counter: int = 0;
name: string = "Jon";
average: float = 0.5 * (x+y);
만일 타입이 생략되면 컴파일러가 값을 가지고 이를 추론합니다.
counter := 0; // an int
name := "Jon"; // a string
average := 0.5 * (x+y); // a float
만일 값이 생략되면 여러분은 초기화 없이 선안만 하게 됩니다.
counter: int;
name: string;
average: float;
이러한 모든 것들은 아마도 여러분들이 쓰던 것과 반대일 것입니다만, 러닝 커브는 좁고 여러분은 이를 빠르게 습득할 수 있을 것입니다. 함수 선언은 이렇게 생겼습니다:
// A function that accepts 3 floats as parameters and returns a float
sum := (x: float, y: float, z: float) -> float {
return x + y + z;
};
print("Sum: %\n", sum(1, 2, 3));
그리고 구조체 선언은 이렇습니다:
Vector3 := struct {
x: float;
y: float;
z: float;
};
배열은 이렇게 만들 수 있습니다:
a: [50] int; // An array of 50 integers
b: [..] int; // A dynamic array of integers
배열은 C에서와 같이 자동으로 포인터로 캐스팅되지 않습니다. 그보다는 배열 크기 정보를 갖고 있는 “넓은 포인터(wide pointer)”입니다. 합수는 배열 타입을 인자로 가질 수 있고 배열의 크기를 알아낼 수 있습니다.
print_int_array :: (a: [] int) {
n := a.count;
for i : 0..n-1 {
print("array[%] = %\n", i, a[i]);
}
}
배열의 크기 정보를 유지하는 것은 개발자가 추가 파라미터로 배열 길이를 넘기는 패턴을 피할 수 있도록 해주며 자동 바운드 체크를 돕습니다. (Walter Bright - C’s Biggest Mistake를 참고하세요.)
임의 컴파일-타임 코드 실행
제가 선형 컬러값을 sRGB로 바꾸는 코드를 C로 작성하고 십다고 해봅시다. 이는 pow() 함수를 사용해야하는데, 비싼 축에 속하는 함수지요. 우리는 런타임에 pow를 쓰는 대신 직접 계산하고 결과를 우리 프로그램의 일부분이 되도록 하여 직접적으로 pow() 함수를 사용하는걸 피할 수 있습니다. 그러니까 값이 들어있는 테이블을 만들고 이를 리턴하는 거지요.
#define SRGB_TABLE_SIZE 256
float srgb_table[SRGB_TABLE_SIZE] = { /* ... values here ... */ }
float linear_to_srgb(float f)
{
// Find the index in our table for this SRGB value,
// assuming f is in the range [0, 1]
int table_index = (int)(f * SRGB_TABLE_SIZE);
return srgb_table[table_index];
}
(노트: 위 코드는 나쁜 코드고, 예시용으로만 사용됩니다. 더 나은 코드를 위해서라면, stb_image_resize의 sRGB 함수를 이용해보세요.) 여기까지는 좋은데, srgb_table의 값을 어떻게 계산해야 할까요? 값을 출력할 다른 작은 프로그램을 작성할 수 있겠죠. 예를 들자면:
float real_linear_to_srgb(float f)
{
if (f <= 0.0031308f)
return f * 12.92f;
else
return 1.055f * (float)pow(f, 1 / 2.4f) - 0.055f;
}
#define SRGB_TABLE_SIZE 256
int main(int c, char* s) {
printf("float srgb_table[SRGB_TABLE_SIZE] = { ");
for (int i = 0; i < SRGB_TABLE_SIZE; i++)
printf("%f, ", real_linear_to_srgb((float)i/SRGB_TABLE_SIZE));
printf("}\n");
return 0;
}
우리는 이 작은 프로그램을 컴파일할 수 있고, 이는 sRGB 값의 테이블을 출력할 거고, 우리는 이제 실제 우리가 만들 프로그램에 출력값을 복사해 넣을 수 있을 겁니다.
이런 접근은 문제들이 들어있는 큰 양동이처럼 됩니다. 예를 들면, 실제 프로그램과 도우미 프로그램에 각각 한번씩 SRGB_TABLE_SIZE가 두번 정의되어 있는걸 보시죠. 그러니까 우리는 이제 두 개의 분리된 소스 코드를 유지해야 하는 것이죠. 이는 큰 문제를 해결하고자 할 경우 매우 거추장스러울 수 있습니다.
Jai에서는 같은 작업을 이렇게 할 수 있습니다:
generate_linear_srgb := () -> [] float {
srgb_table: float[SRGB_TABLE_SIZE];
for srgb_table {
<< it = real_linear_to_srgb(cast(float)it_index / SRGB_TABLE_SIZE)
}
return srgb_table;
}
srgb_table: [] float = #run generate_linear_srgb(); // #run invokes the compile time execution
real_linear_to_srgb := (f: float) -> float {
table_index := cast(int)(f * SRGB_TABLE_SIZE);
return srgb_table[table_index];
}
#run 지시자는 Jai에게 generate_linear_srgb() 함수가 컴파일 타임에 실행되는 것이라 알려줍니다. Jai의 컴파일-타임 함수 실행은 컴파일 타임에 명령어를 실행하여 테이블의 값을 반환하고, 이는 이후 srgb_table의 바이너리 형태로 컴파일됩니다. 프로그램이 실행되면, generate_linear_srgb()함수는 더 이상 존재하지 않게 됩니다. 오직 이 함수가 만들어낸 테이블만이 존재하게 되고, 이는 linear_to_srgb() 함수가 사용하죠.
컴파일-타임 함수 실행은 거의 제한이 없습니다; 사실, 여러분은 여러분의 코드중 임의의 부분을 컴파일러의 일부분처럼 실행할 수 있습니다. Blow의 첫 데모에서 그는 게임 전체가 컴파일러의 일부분으로서 실행되는 것, 그리고 게임으로부터 데이터를 구워 프로그램 바이너리로 넣는 것을 보여주었습니다. (전 #run invaders();가 언어에 수입되길 바랍니다.) 컴파일러는 컴파일-타임에 실행되는 함수를 특별한 바이트코드 언어로 빌드하고 이를 인터프리터에서 실행하며, 결과는 다시 소스코드로 돌아오게 됩니다. 컴파일러는 그 후 평범하게 동작합니다.
컴파일-타임 함수가 할 수 있는 몇가지 예를 나열해보자면 아래와 같습니다:
- 컴파일 타임 어서트(asserts)
- 테스트 케이스 실행
- 코드 스타일 체크
- 동적으로 코드를 만들어 컴파일되도록 하기
- 빌드 타임에 데이터 삽입
- OpenGL 스펙을 다운로드 받아서 가장 최신의 gl.h 헤더 파일 만들기
- 빌드 서버에 접속하여 빌드 데이터 보내기
- 화성에 있는 여러분의 화성 탐사선에게 말하여 돌아와서 화성이 어찌 생겼는지 사진을 가져오라고 하는 패킷 기다리라고 하기
코드 리팩토링
모든 코드는 더 일반적인 경우에서의 사용을 위해 옮겨지기 전까지 어떤 종류의 코드 블록 안에서 그 인생을 시작합니다. Jai는 몇가지 특별한 문법으로 프로그래머가 코드를 특별한 경우에서 일반적인 경우로 옮길 수 있게 하여 코드 재사용을 촉진시킵니다.
한 가지 예로, 여러분이 아래와 같은 코드를 작성했다고 칩시다:
draw_particles := () {
view_left: Vector3 = get_view_left();
view_up: Vector3 = get_view_up();
for particles {
// Inside for loops the "it" object is the iterator for the current object.
particle_left := view_left * it.particle_size;
particle_up := view_up * it.particle_size;
// m is a global object that helps us build meshes to send to the graphics API
m.Position3fv(it.origin - particle_left - particle_up);
m.Position3fv(it.origin + particle_left - particle_up);
m.Position3fv(it.origin + particle_left + particle_up);
m.Position3fv(it.origin - particle_left + particle_up);
}
}
이 메쉬 생성 콜은 실제로 일반적인 사각형 렌더링의 특별한 경우에 해당하고, 그러므로 이 코드는 다른 함수로서 리팩토링 되어 다른 곳에서도 쓸 수 있습니다. Jai는 이런 리팩토링을 매우 직관적으로 만들어줍니다. 첫번째 단계는 특별한 캡처 문법을 이용해 새로운 스코프 내에 코드를 집어넣는 것입니다.
particle_left := view_left * it.particle_size;
particle_up := view_up * it.particle_size;
origin := it.origin;
[m, origin, particle_left, particle_up] {
m.Position3fv(origin - particle_left - particle_up);
m.Position3fv(origin + particle_left - particle_up);
m.Position3fv(origin + particle_left + particle_up);
m.Position3fv(origin - particle_left + particle_up);
}
(Disclamer: 이 단계는 Blow가 아직 구현하지 않았습니다. 그가 계획한 피쳐 중 하나입니다.) [m, origin, particle_left, particle_up 노테이션은 이 새로운 스코프 내에서 캡처 되지 않은 오브젝트들이 접근되지 않도록 보호해주는 캡처입니다. it.origin이 origin으로 바뀌어야 되고 origin을 캡처 리스트에 추가해야 하는 점을 주목하세요. it는 캡처되지 않고 스코드 안에서 사용될 수 없습니다.
캡처는 우리가 보고 있는 것과 같이 코드를 리팩토링하는 것을 돕지만 다른 방식으로도 도움을 줄 수 있습니다. 예를 들어, 프로그래머가 코드를 싱글스레드에서 멀티스레드로 옮기고 있을 때, 캡처는 스레드에 한정된 데이터만 접근할 수 있도록 강제할 수 있습니다. 캡처는 캡처 내의 코드가 캡처로 지정한 상태만을 읽고 쓸수 있도록 해주는 보험 정책입니다.
이제 우리는 외부의 것들에 의존적인 우리 코드의 모든 부분을 확인할 수 있으므로, 우리는 우리 코드의 상태를 개선 시키고 이 코드를 함수로부터 끌어내기 쉽게 해왔습니다. 이제 우리는 개속해서 이 쿼드 그리기 코드가 다른 곳에서 사용될수 있도록 하고 싶습니다. 그리하여 우리는 이 블록 캡처 밖에 함수를 만듭니다:
particle_left := view_left * it.particle_size;
particle_up := view_up * it.particle_size;
origin := it.origin;
() [m, origin, particle_left, particle_up] {
m.Position3fv(origin - particle_left - particle_up);
m.Position3fv(origin + particle_left - particle_up);
m.Position3fv(origin + particle_left + particle_up);
m.Position3fv(origin - particle_left + particle_up);
} (); // Call the function
함수 문법 ()을 추가하기 위해 어느 정도의 변경만이 필요한지 주목하세요. 캡처 구문은 손상되지 않은 채로 남았습니다. 그리하여 매우 적은 노력만으로 블록 캡처는 함수로 변경됩니다. 이제 벡터들을 함수의 파라미터로 옮기고 싶다면:
(origin: Vector3, left: Vector3, up: Vector3) [m] {
m.Position3fv(origin - left - up);
m.Position3fv(origin + left - up);
m.Position3fv(origin + left + up);
m.Position3fv(origin - left + up);
}
파라미터 이름들을 가지고 우리는 새로운 함수에 맞도록 함수 내 사용된 변수들의 이름을 바꿀 수 있습니다. 이제 우리는 파티클 뿐만 아니라 어떤 종류에 대한 쿼드도 그릴 수 있는 함수로 이용할 수 있습니다. 캡처는 m을 유지 시키는데 그 이유는 이게 파라미터로서 집어넣을 필요가 없는 전역 오브젝트이기 때문입니다. 그리고 이제 우리는 드로잉 코드 내에서 사용될 수 있는 익명의 지역 스코프 함수를 갖게 되었습니다:
draw_particles := () {
view_left: Vector3 = get_view_left();
view_up: Vector3 = get_view_up();
for particles {
particle_left := view_left * it.particle_size;
particle_up := view_up * it.particle_size;
(origin: Vector3, left: Vector3, up: Vector3) [m] {
m.Position3fv(origin - left - up);
m.Position3fv(origin + left - up);
m.Position3fv(origin + left + up);
m.Position3fv(origin - left + up);
} (origin, particle_left, particle_up); // Call the function with the specified parameters
}
}
익명 함수는 다른 함수들에 인자로 보내기 유용하고, 이런 문법은 이것들을 만들거나 유지보수하기 쉽게 해둡니다. 다음 단계는 함수 이름을 지정하는 것입니다:
draw_quad := (origin: Vector3, left: Vector3, up: Vector3) [m] {
m.Position3fv(origin - left - up);
m.Position3fv(origin + left - up);
m.Position3fv(origin + left + up);
m.Position3fv(origin - left + up);
}
draw_quad(origin, particle_left, particle_up);
이제 우리는 원한다면 지역 스코프 내에서 여러번 이 함수를 호출할 수 있습니다. 하지만 우리는 전역 스코프에서 이 함수에 접근하고 싶어합니다. 지역 스코프 밖으로 함수를 옮기는 일은 함수 내의 코드를 전혀 건드리지 않습니다:
draw_quad := (origin: Vector3, left: Vector3, up: Vector3) [m] {
m.Position3fv(origin - left - up);
m.Position3fv(origin + left - up);
m.Position3fv(origin + left + up);
m.Position3fv(origin - left + up);
};
draw_particles := () {
view_left: Vector3 = get_view_left();
view_up: Vector3 = get_view_up();
for particles {
particle_left:= view_left * it.particle_size;
particle_up:= view_up * it.particle_size;
draw_quad(particle_left, particle_up, origin);
}
}
Jai의 함수 문법의 강점은 함수가 익명이건 지역 함수건(즉 다른 함수 내의 스코프에서만 살아있는 함수), 클래스의 멤버 함수건, 혹은 전역 함수건 상관없이 변치 않는다는 점입니다. 이는 C++와는 대비되는 지점인데, C++은 지역 함수가 람다라고 불리고 클래스 이름과 :: 연산자 등을 사용해야 하는 멤버 함수 선언과 아무런 클래스 이름과 :: 없이 선언하는 등과 다릅니다. 결과는 코드가 성숙해지고 로컬 콘텍스트에서 글로벌 콘텍스트로 이동되면서 리팩토링 작업이 최소한의 수정으로 이뤄질 수 있습니다.
여기 Jai의 코드 성숙 과정(code maturation cycle)을 모두 담아보았습니다:
{ ... } // Anonymous code block
[capture] { ... } // Captured code block
(i: int) -> float [capture] { ... } // Anonymous function
f := (i: int) -> float [capture] { ... } // Named local function
f := (i: int) -> float [capture] { ... } // Named global function
통합 빌드 과정
프로그램을 빌드하는 모든 정보는 프로그램의 소스 코드 내에 담겨 있습니다. 그러므로 make 커맨드나 Jai 프로그램을 빌드하기 위한 프로젝트 파일이 필요 없습니다. 간단한 예를 들면:
build :: () {
build_options.executable_name = "my_program";
print("Building program '%'\n", build_options.executable_name);
build_options.optimization_level = Optimization_Level.DEBUG;
build_options.emit_line_directives = false;
update_build_options();
// Jai will automatically build any files included with the #load directive, but other files can also be manually added
add_build_file("misc.jai");
add_build_file("checks.jai");
}
#run build();
프로그램이 빌드될 때, #run 지시어가 build() 함수를 컴파일 타임에 실행시킵니다. 그러면 build() 함수가 프로젝트를 위한 모든 빌드 옵션을 정립합니다. 다른 어떠한 외부 빌드 도구도 필요없고, 모든 빌드 스크립트 작업은 Jai 내에서, 그리고 코드의 다른 부분에서도 같은 환경에서 이뤄지게 됩니다.
데이터 지향 구조
SOA와 AOS
현대의 프로세서들과 메모리들은 데이터가 공간적 지역성(spatial locality)이 있을 때 훨씬 빨라집니다. 이는 즉 한번에 같이 수정될 데이터들끼리 묵여있으면 성능에 이점을 준다는 말입니다. 따라서 구조체의 배열(array of structures, AoS) 방식의 구조를:
struct Entity {
Vector3 position;
Quaternion orientation;
// ... many other members here
};
Entity all_entities[1024]; // An array of structures
for (int k = 0; k < 1024; k++)
update_position(&all_entities[k].position);
for (int k = 0; k < 1024; k++)
update_orientation(&all_entities[k].orientation);
배열의 구조체(structure of arrays, SoA) 방식으로 바꾸면:
struct Entity {
Vector3 positions[1024];
Quaternion orientations[1024];
// ... many other members here
};
Entity all_entities; // A structure of arrays
for (int k = 0; k < 1024; k++)
update_position(&all_entities.positions[k]);
for (int k = 0; k < 1024; k++)
update_orientation(&all_entities.orientations[k]);
캐시 미스가 줄어드는 이유로 성능 향상을 끌어낼 수 있습니다.
그러나, 이런 방식은 프로그램이 점점 커지면서 데이터를 재구성하는 것이 더 어려워지게 됩니다. 딱 하나의 간단한 변경이 성능에 어떠한 영상을 주는지 테스트 해보는 것일지라도 개발자가 많은 시간을 소모하게 하는데, 그 이유는 데이터 구조가 한번 바뀌게 되면, 해당 데이터를 바탕으로 동작하는 코드의 모든 부분이 깨지기 때문입니다. 그래서 Jai에서는 코드가 깨지지 않으면서도 SoA와 AoS 사이의 변환을 자동으로 해주는 매커니즘을 제공합니다. 예를 들면 이렇게요:
Vector3 :: struct {
x: float = 1;
y: float = 4;
z: float = 9;
}
v1 : [4] Vector3; // Memory will contain: 1 4 9 1 4 9 1 4 9 1 4 9
Vector3SOA :: struct SOA {
x: float = 1;
y: float = 4;
z: float = 9;
}
v2 : [4] Vector3SOA; // Memory will contain: 1 1 1 1 4 4 4 4 9 9 9 9
우리의 예전 예제로 돌아가서, Jai에서는 아래처럼 작성할 수 있습니다:
Entity :: struct SOA {
position : Vector3;
orientation : Quaternion
// .. many other members here
}
all_entities : [4] Entity;
for k : 0..all_entities.count-1
update_position(&all_entities[k].position);
for k : 0..all_entities.count-1
update_orientation(&all_entities[k].orientation);
이제 SoA와 AoS 사이를 변환하는데 필요한 변경사항은 SOA 키워드를 구조체 선언 부에 집어넣거나 제거하는 것만으로 할 수 있으며, Jai는 그 외의 모든 작업을 뒤에서 기대했던 바와 같이 동작하게 할 것입니다.
리플렉션과 런타임 타입 정보
Jai는 각 컴파일된 프로그램의 데이터 세그먼트에 모든 타입 정보를 담은 테이블을 저장합니다. 이는 다음과 같이 실험 가능합니다:
for _type_table {
// it is the iterator, it is the Type being examined. it_index is the iteration index, it is an integer
print("%:\n", it_index);
print(" name: %\n", it.name);
print(" type: %\n", it.type); // type is an enum, INTEGER, FLOAT, BOOL, STRUCT, etc
}
모든 구조체, 함수, 열거형에 대하여 모든 내부 데이터가 접근 가능합니다. 예를 들면, 어떤 프로시져는 아래와 같이 생겼을 수도 있습니다:
print("% (", info_procedure.name);
for info_procedure.argument_types {
print_type(it);
if it_index != info_procedure.argument_types.count-1 then print(", ");
}
print(") ->");
print_type(info_procedure.return_type);
이 코드는 get_name(id: uint32) -> string 같은 종류의 것을 출력할 수 있습니다. 열거형은 아래처럼 실험 가능합니다:
Hello :: enum u16 {
FIRST,
SECOND,
THIRD = 80,
FOURTH,
}
for Hello.names {
print("Name: % value: %\n", Hello.names[it_index], Hello.values[it_index]);
}
이러한 데이터 리플렉션은 개체의 네트워크 반응과 게임 데이터 등에서 자주 사용되는 직렬화(serialization) 프로시져를 작성하는데 사용될 수 있습니다. 이러한 일을 하는데에 있어 현재의 C/C++ 함수들은 연산자 오버로딩과 프리프로세서 구절을 과하게 사용해야 합니다.
다형적 프로시져
함수 다형성
Jai의 제 1 다형성 메카니즘은 함수 레벨에 있으며, 예시로 가장 잘 설명할 수 있습니다:
sum(a: $T, b: T) -> T {
return a + b;
}
f1: float = 1;
f2: float = 2;
f3 := sum(f1, f2);
i1: int = 1;
i2: int = 2;
i3 := sum(i1, i2);
x := sum(f1, i1);
print("% % %\n", f3, i3, x); // Output is "3.000000 3 2.000000"
sum() 함수가 호출되면, $ 기호 다음에 나오는 T에 의해 타입이 결정됩니다. 위 경우 a 변수 다음에 $가 나왔고, 그러므로 T 타입은 첫번째 파라미터로 결정됩니다. 그러니까 첫번째 sum() 호출은 float + float이고, 두번째 호출은 int + int가 됩니다. 세번째 호출에서는, 첫번째 파라미터가 float이므로, 두 파라미터와 리턴값 모두 float이 됩니다. 두 번째 파라미터는 int에서 float으로 형변환이 이루어지고, x 변수도 마찬가지로 float이 됩니다.
Any 타입
Jai는 Any라고 부르는 타입을 갖고 있는데, 이는 다른 타입들이 암묵적으로 형변환될 수 있는 타입입니다. 예를 들면:
print_any(a: Any) {
if a.type.type == Type_Info_Tag.FLOAT
print("a is a float\n");
else if a.type.type == Type_Info_Tag.INT
print("a is an int\n");
}
baking
(역주: 원저자가 아직 작성을 못한듯)… 음 이 섹션은 아직 못썼습니다! 죄송합니다. (#bake 구절이 인자와 결합된 함수를 구워내는 형태입니다. 예를 들면 #back sum(a, 1)은 a += 1과 같은 형태가 됩니다.)
메모리 관리
Jai는 가비지 콜렉션이나 다른 어떤 종류의 자동 메모리 관리 기능도 구현하지 않을 것입니다.
구조체 포인터 소유권
구조체의 포인터 멤버에 대해 !을 붙이면 해당 포인터가 가리키고 있는 오브젝트는 이 구조체에 소유됨을 나타내며, 이 구조체가 할당 해제 될 때 함께 지워져야 함을 뜻합니다. 예를 들면:
node := struct {
owned_a : node *! = null;
owned_b : node *! = null;
};
example: node = new node;
example.owned_a = new node;
example.owned_b = new node;
delete example; // owned_a and owned_b are also deleted.
owned_a와 owned_b는 node에 의해 소유된 것으로 표시되었고, node가 지워질 때 함께 자동적으로 지워지게 됩니다. C++에서 이는 unique_ptr<T>를 이용해 할 수 있지만, Blow는 이것이 이런 일을 하는데 있어 잘못된 방법이라고 생각하는데 그 이유는 템플릿 기반의 접근법이 해당 오브젝트의 진짜 타입을 덧씌워버리기 때문입니다. unique_ptr<node>는 더 이상 node가 아니죠- 이것은 node의 가면을 쓰고 있는 unique_ptr일 뿐입니다. node*의 타입과 node*의 속성을 유지시키는 것이 바람직하지만, unique_ptr과 함께로서는 부적절해보이는데, 그 이유는 우리가 unique_ptr가 그것의 방식대로 처리될지 고려하지 않아도 되어야 하기 때문입니다.
라이브러리 할당자(Library allocator)
(역주: 원저자가 아직 작성을 못한듯)… 음 이 섹션은 아직 못썼습니다! 죄송합니다. (Jai는 라이브러리 작성자로부터 필요로하는 작업 없이 임포팅된 라이브러리를 할당하는 관리를 위한 메카니즘을 제공합니다.)
초기화
클래스의 멤버 변수들은 자동적으로 초기화됩니다.
Vector3 :: struct {
x: float;
y: float;
z: float;
}
v : Vector3;
print("% % %\n", v.x, v.y, v.z); // Always prints "0 0 0"
여러분은 디폴트 초기값으로 이를 대신할 수 있습니다:
Vector3 :: struct {
x: float = 1;
y: float = 4;
z: float = 9;
}
v : Vector3;
print("% % %\n", v.x, v.y, v.z); // Always prints "1 4 9"
va : [100] Vector3; // An array of 100 Vector3
print("% % %\n", va[50].x, va[50].y, va[50].z); // Always prints "1 4 9"
혹은 여러분은 디폴트 초기화를 막을수도 있습니다 (역자: 헉?!):
Vector3 :: struct {
x: float = ---;
y: float = ---;
z: float = ---;
}
v : Vector3;
print("% % %\n", v.x, v.y, v.z); // Undefined behavior, could print anything
여러분은 변수 선언 부분에서도 디폴트 초기화를 막을 수 있습니다:
Vector3 :: struct {
x: float = 1;
y: float = 4;
z: float = 9;
}
v : Vector3 = ---;
print("% % %\n", v.x, v.y, v.z); // Undefined behavior, could print anything
va : [100] Vector3 = ---;
print("% % %\n", va[50].x, va[50].y, va[50].z); // Undefined behavior, could print anything
인라인 적용
test_a :: () { /* ... */ }
test_b :: () inline { /* ... */ }
test_c :: () no_inline { /* ... */ }
test_a(); // Compiler decides whether to inline this
test_b(); // Always inlined due to "inline" above
test_c(); // Never inlined due to "no_inline" above
inline test_a(); // Always inlined
inline test_b(); // Always inlined
inline test_c(); // Always inlined
no_inline test_a(); // Never inlined
no_inline test_b(); // Never inlined
no_inline test_c(); // Never inlined
추가적으로, 어떤 프로시져를 항상 인라인화 시키거나 인라인화 시키지 않도록 하는 구절이 있는데, 이는 플랫폼 별로 조건에 따라 인라인화 시키거나 하지 않도록 만드는 것을 쉽게 합니다.
test_d :: () { /* ... */ }
test_e :: () { /* ... */ }
#inline test_d // Directive to always inline test_d
#no_inline test_e // Directive to never inline test_e
다른 멋진 기능들
C/C++이 오래전부터 갖고 있었던 것들:
- 멀티 라인 블록 주석
- 네스티드 블록 주석
- 8, 16, 32비트 정수를 위한 특정 데이터 타입
- 암묵적 형변환 없음
- 헤더 파일 없음
- 구조체 멤버 및 포인터 역참조 접근 모두
. 연산자 사용: ->은 이제 그만
defer 구문, Go의 그것과 비슷함
게획된 기능들
Blow가 Jai를 위해 가지고 있는 몇가지 피쳐들을 나열해보면 다음과 같습니다:
- 자동화된 빌드 관리 - 프로그램이 어떻게 빌드되는지 특정합니다.
- 캡처
- LLVM 통합
- 자동 버전 관리 (아래 참조)
- 더 나은 동시성 모델
- 이름이 붙은 인자 넘기기 (Named argument passing)
- 허용된 라이센스
계획에 없는 것들
Jai는 앞으로 아래 것들이 없을 것입니다.
- 스마트 포인터
- 가비지 콜렉션
- 어떠한 종류에 상관없이 자동적 메모리 관리
- 템플릿과 템플릿 메타 프로그래밍
- RAII
- 생성자와 소멸자
- 서브타입 다형성
- 예외처리
- 참조자(References)
- 가상 머신 (최소, 자주는 아니게끔- 아래 참조)
- 프리프로세서 (최소, C와 같지는 않게끔- 아래 참조)
- 헤더 파일
만일 여러분이 Jai가 현대적인 고수준 언어인데도 저런 기능이 없다는 것에 대해 이상하다고 들리신다면, Jai가 Java나 C# 만큼 고수준을 시도하는 것이 아니라는 점을 고려하세요. Jai는 더 나은 C를 만들기 위한 노력이라고 표현하는 것이 더 맞습니다. 이는 프로그래머가 그들이 원하는 수준에서의 저수준 접근을 하도록 해주길 원합니다. 가비지 콜렉션과 예외처리 같은 기능은 저수준 프로그래밍에 장애물로 동작할 수 있습니다.
그밖에
채택
게임을 위한 완전히 새로운 언어를 작성하지 말라는 강압적인 요구는 현재의 게임 엔진 내에서 C와 C++ 코드의 모멘텀과 볼륭이 너무나 크고, 새로운 언어로 바꾸는 것이 이익의 총량에 비해 너무 많은 작업을 수행하게 된다는 것으로부터 비롯된 것입니다. Blow는 엔진들이 어쨌든 그들의 코드 베이스를 주기적으로 다시 작성해야 한다고 주장하며, Jai와 C가 서로 밀접하게 연관되어 있기 때문에 C 코드와 Jai 코드는 개별적으로 생존 가능하면서 일상적으로 일어나는 재작성된 코드가 자리 잡을 수 있게 됩니다. C와 Jai는 매끈하게 상호 작동하기 때문에, Jai 코드는 존재하는 C 라이브러리의 윗단에서 빌드될 수 있습니다. 사실, Blow는 그의 Jai 테스트 코드를 위해 OpenGL과 stb_image의 C 인터페이스를 이용합니다. 그러므로, 개발하는데 더 많은 비용없이 C와 C++을 대체하는 것이 가능합니다. 한편, C의 모든 장점을 가지면서 단점이 거의 없는 언어로 C를 대체하는 것의 이점은 곧 프로그래머가 더 행복해질 것이란 의미이며, 따라서 더 생산적이게 될 것입니다.
왜 C++/Rust/Go/D/Swift/Haskell/Lisp/기타를 안쓰나?
이 언어들은 매우 강력하지만, 이중 어떤 언어도 게임 프로그래머가 필요로 하는 올바른 기능 조합 (혹은 기능의 부재)를 갖추고 있지 못합니다. 자동적 메모리 관리는 메모리 레이아웃을 직접 제어하길 원하는 게임 프로그래머에게 있어 기초 도구가 아닙니다. 다른 인터프리터 언어들은 너무 느릴 것입니다. 함수형만 제공하는 언어(Functional-only language)는 무의미하게 제한적입니다. 객체 지향만 제공하는 언어(Objec-oriented-only language)는 너무 복잡합니다. Blow는 게임 프로그래머가 필요로 품질을 갖추고, 필요로 하지 않는 품질은 없앤 새로운 언어를 개발하길 원합니다.
제안하는 기능
이들은 Blow가 제안했으나 아직 구현되지 않은 몇몇 기능들입니다. 제 지식 안에서 이들은 언어 내에 없습니다. 문법은 초안이며 변경될 수 있습니다.
첫번째는 결합 할당(joint allocation)입니다:
Mesh :: struct {
name: string;
filename: string;
flags: uint;
positions: [] Vector3;
indices: [] int; @joint positions
uvs: [] Vector2; @joint positions
};
example_mesh: Mesh;
example_mesh.positions.reserve(positions: num_positions,
indices: num_indices,
uvs: num_uvs);
여기서 우리는 여러번의 메모리 할당을 피하고 싶고, 그래서 우리는 컴파일러가 positions과 indices, uvs를 함게 할당하여 메모리를 그에 맞게 나누도록 하게 합니다. 현재 이는 C를 이용해 수동적으로 되고 있고, 에러를 내기 쉽습니다.
다음은 옵셔널 타입입니다:
do_something := (a: Entity?) {
a.x = 0; // ERROR!
if (a) {
a.x = 0; // OK
}
};
여기의 아이디어는 가장 흔한 크래쉬 사유중 하나인 널 포인터 역참조를 막는 것입니다. 위의 코드에서 ?가 의미하는 것은 포인터가 null인지 아닌지 모른다는 것입니다. 이것이 null인지 테스트하지 않고 역참조를 시도하는 것은 컴파일 타임 에러를 만들게 됩니다.
마지막으로, 자동 버저닝입니다:
Entity_Substance :: struct { @version 37
flags: int;
scale_color: Vector4; @15
spike_flags: int; @[10, 36]
};
여기서 Blow는 그의 데이터 구조에 대헤 구조체의 각 멤버가 어떤 버젼으로 제공되었는지를 컴파일러에게 알려주는 마크업을 제공하고 있습니다. 이러한 버져닝 스킴은 자동적인 serialization/introspection 인터페이스의 부분으로 사용될 것이지만, 그는 이 언어가 introspection과 관련한 기능을 가지게 될 것이라는 점 외에 더이상의 자세한 설명을 언급하진 않았습니다.
Comment count